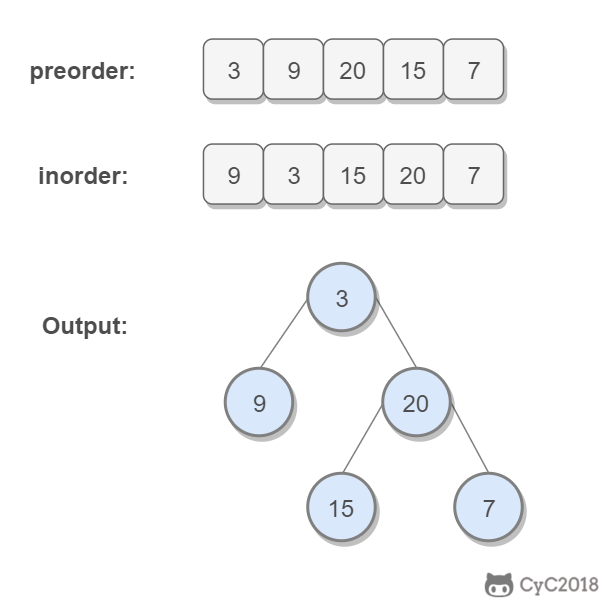
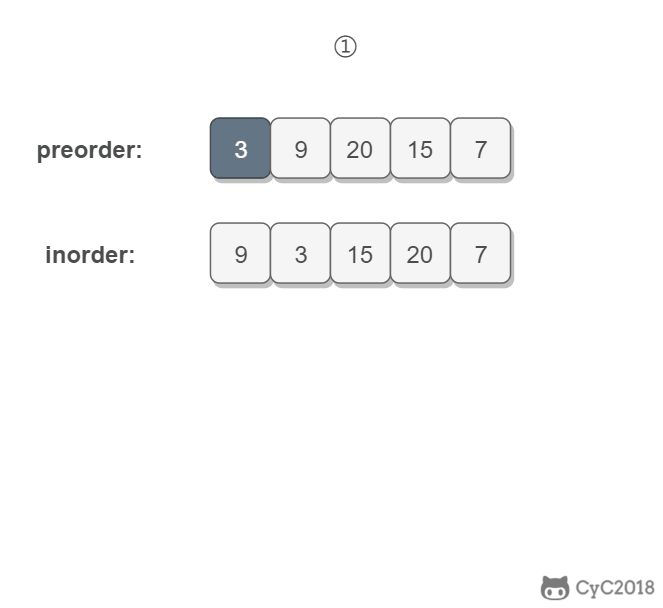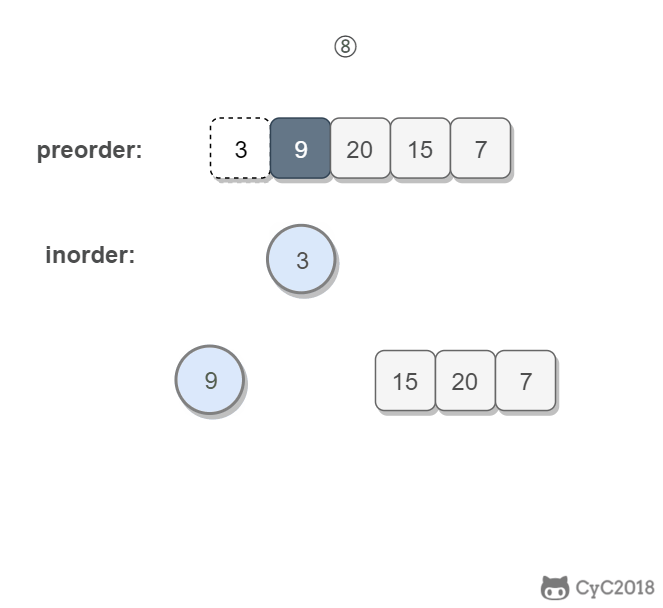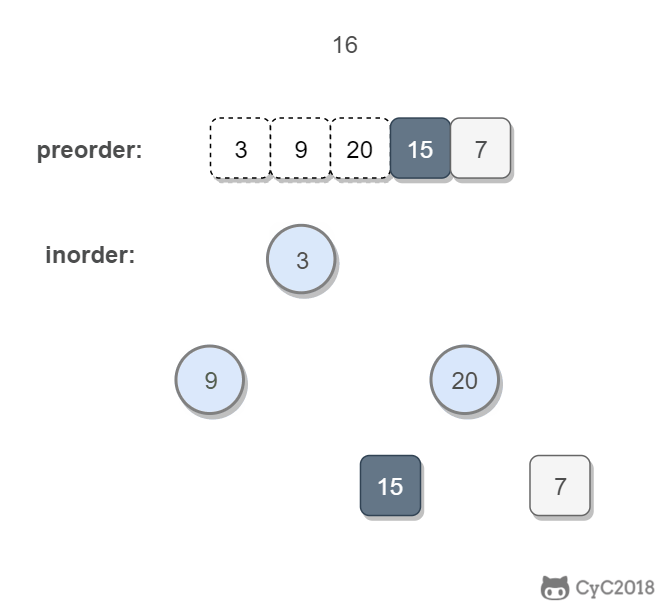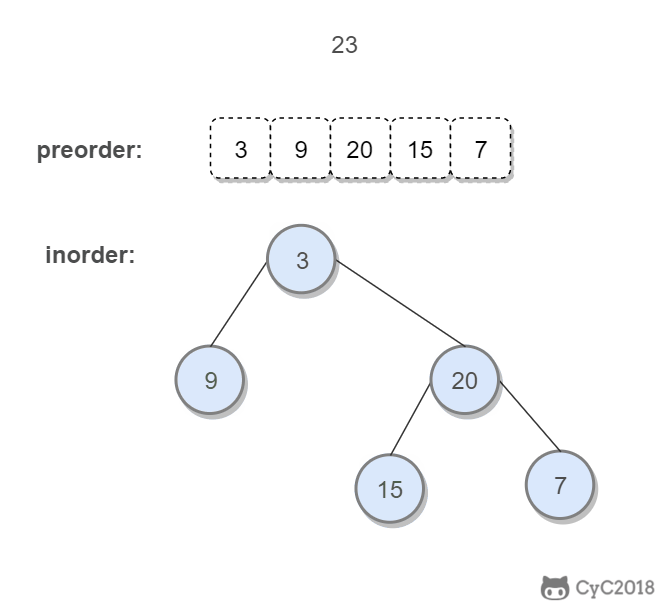
首先通过一个简单的例子看看泛型的基本使用。假如我们要创建一个礼物对象,但是礼物有很多种,可以是电脑,自行车或者是别的乱七八糟的任何东西。那么这个时候我们怎么描述礼物对象中内容呢?好像用object可以,但是每次使用object都要做强制类型转换,如果转换出错甚至要到运行时才能检测出来。那么这种情况我们就应该考虑用泛型来处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public class Gift<T> {
private final T value;
private final Double cost;
public Gift(T value,Double cost){
this.value=value;
this.cost=cost;
}
public T getValue(){
return value;
}
public Double getCost(){
return cost;
}
}
public class GiftGiver {
Computer computer=new Computer();
Gift<Computer> giftToJon=new Gift<Computer>(computer,1500d);
Bicycle bicycle=new Bicycle();
Gift<Bicycle> giftToBob=new Gift<Bicycle>(bicycle,500d);
Computer jonGift=giftToJon.getValue();
Bicycle bobGift=giftToBob.getValue();
}
|
从上面的代码可以看出,我们使用泛型的时候只需要在调用的时候指出泛型类型就可以了。接下来我们看看泛型的特征
1.一个类或者接口可以有0或者多个泛型类型
2.通常用一个字母来表示泛型类型(编译器当然不在乎你用多个,你可以用Cat,Dog来表示泛型,但是这样可读性会变差。读者会认为泛型里面只能是你写的那个类,但是实际上你用的是泛型)
3.带泛型的类型不能保持其原继承关系(下面的例子有讲解)
4.泛型里面的内容本身可以是某类的子类或者父类
例子:
1
| <T extends Computer> or <T super Computer>
|
5.泛型类型会在编译时被擦除(从JVM的视角来看,泛型压根不存在)
6.不能实例化类型变量
public Pair(){
first=new T();//error
second=new T();//error
}
下面来通过一个例子来解释第三条
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| public class Echo<T> {
public T echo(T value){
return value;
}
public Echo<T> echo(Echo<T> value){
return value;
}
}
public class EchoChamber {
public static void main(String[] args) {
Echo<Number> numberEcho=new Echo<>();
numberEcho.echo(10);
numberEcho.echo(10d);
numberEcho.echo(10f);
numberEcho.echo(10L);
numberEcho.echo(new Echo<Integer>());
numberEcho.echo(new Echo<Double>());
numberEcho.echo(new Echo<Float>());
numberEcho.echo(new Echo<Long>());
}
}
|
泛型的这个特征我们把它叫做invariant的。这一点和数组是反着的,数组我们叫covariant.因为我们学数组的时候都知道,如果A继承数组B,那么A类型的数组也可以在多态中替代B类型的数组。无论S与T有什么联系,echo与echo都没有什么联系。
在非泛型类中也可以使用泛型方法
1
2
3
4
5
6
7
8
9
| public class ArrayAlg {
public static void main(String[] args) {
String middle= ArrayAlg.<String> getMiddle("John","Q.","Public");
System.out.println(middle);
}
public static <T> T getMiddle(T...a){
return a[a.length/2];
}
}
|
在泛型中,一个泛型类型可以被多个条件约束。
1
2
3
4
5
6
7
8
9
10
11
12
|
public class MultipleBounds<T extends Number &Comparable& Serializable> {
private final T number;
public MultipleBounds(T number){
this.number=number;
}
public T getNumber(){
return number;
}
}
|
在泛型中,泛型类型可以被其他泛型类型约束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public class BoundedGenericTypes<T,S extends T> {
private final T value;
private final S subValue;
public BoundedGenericTypes(T value,S subValue){
this.value=value;
this.subValue=subValue;
}
public T getValue(){
return value;
}
public S getSubValue(){
return subValue;
}
}
|
这里插入一个小考题,下面这段代码会被编译通过吗?
1
2
3
| public class GenericsAreNotStatic<T>{
private static T reference;
}
|
答案是不行,因为静态成员是所有类成员公用的,你在这里制定静态成员是泛型的。那么加入我们的对象中一个T取的是String,另一个T取的是Integer,这里就无法确定reference的类型了。
接下来我们看看泛型特征的第五条,泛型类型会在编译时被擦除。那么我们的java编译器是如何处理泛型的呢?
实际上编译器就是帮我们加上了强制类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class RuntimeGenerics<T> {
public static void main(String[] args) {
RuntimeGenerics<Number> runtimeGenericNumber=new RuntimeGenerics<Number>(10);
Number numberValue=runtimeGenericNumber.getValue();
}
private final T value;
public RuntimeGenerics(T value){
this.value=value;
}
public T getValue(){
return value;
}
}
|
由于泛型类型会在编译时被擦除,那么我们可以得到以下几条结论
1.泛型类型的尖括号里不能是基础数据类型(不能在运行时将基础数据类型转换为其autobox后的类型)
2.不能用instance of 来对泛型进行类型检查(instance of 是运行时进行检查)
顺带提一下,getClass总是返回原始类型。例如:
Pair stringPair=…
Pair empolyeePair=…;
if(stringPair.getClass()==employeePair.getClass())//they are equal
比较的结果是true,因为getClass只返回原始类型Pair
3.不能抛出或捕获泛型类的实例(原因同上)
4.不能使用带泛型类型的array(前面提过,array是covariant,generic type是invariant的)
接下来我们看看泛型的继承
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class GenericClass<T> {
private final T value;
public GenericClass(T value){
this.value=value;
}
public T getValue(){
return value;
}
}
public class SubGenericClass<T> extends GenericClass<T> {
public SubGenericClass(T value){
super(value);
}
@Override
public T getValue(){
return super.getValue();
}
}
|
接下来我们来聊java泛型中的重点,通配符。
我们还是先来看一个例子来看看没有通配符会发生什么。
1
2
3
4
5
6
7
8
9
10
11
12
| public class GiftPrinter {
public static void main(String[] args) {
Gift<Computer> computerGift=new Gift<>(new Computer(),1500d);
GiftPrinter printer=new GiftPrinter();
printer.print(computerGift);
}
public void print(Gift<Object> gift){
System.out.printf("%s%n",gift);
}
}
|
那么这个时候通配符的作用就出现了,我们用通配符重写print方法
public void print(Gift<?> gift){
System.out.printf(“%s,%n”,gift);
}
通配符的意思是说我不管你Gift<>尖括号里装什么东西,编译器你都让它通过。
关于通配符有下面一点要注意:
通配符只能用于实例上(不能用于class或者method)
比如,我们不能写 public Class Type,public void methodName()
而这样写就是可以的:public void methodName(Gift<?> gift)
上面的例子中通配符是没有限定条件的,但是我们也可以给通配符加上限定条件,请看下面代码
1
2
3
4
5
6
7
8
9
| public class BoundedWildCard {
public void subClasses(Gift<? extends Number> gift){
}
public void superClasses(Gift<? super Integer> gift){
}
}
|